Onyx Forge | AI Product Factory
Build, train, evaluate, and deploy vertical AI products. From domain expertise to production-ready deployment packages — with cryptographic receipts at every stage. NVIDIA-native by default, runs locally on your own hardware — RTX workstations or Apple Silicon.
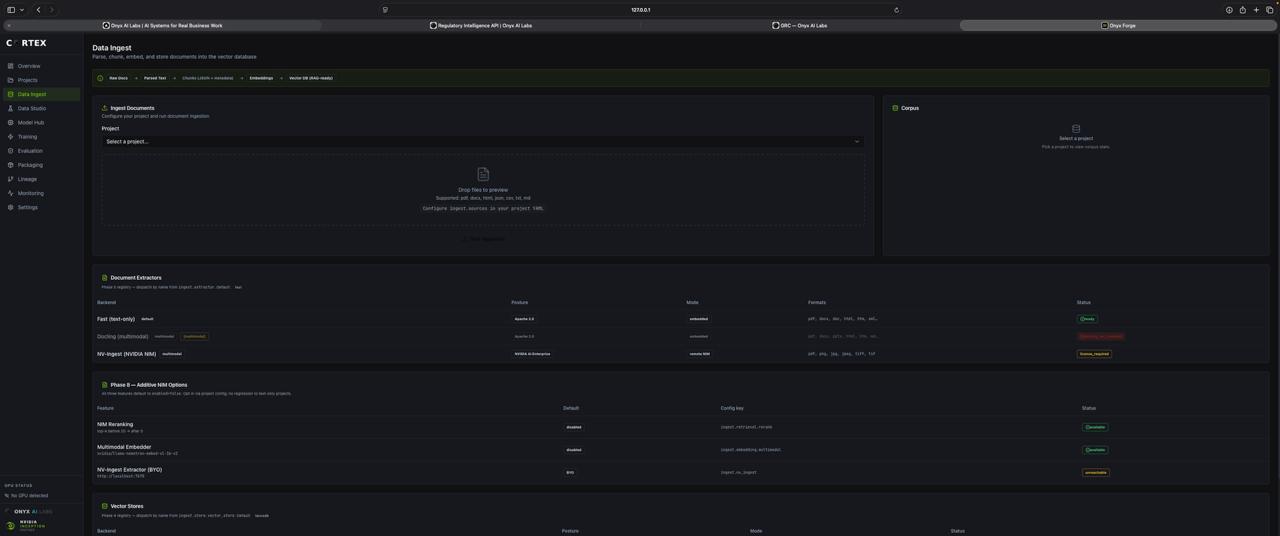
Data Ingest view — a real 10-document corpus chunked, embedded, and stored in LanceDB
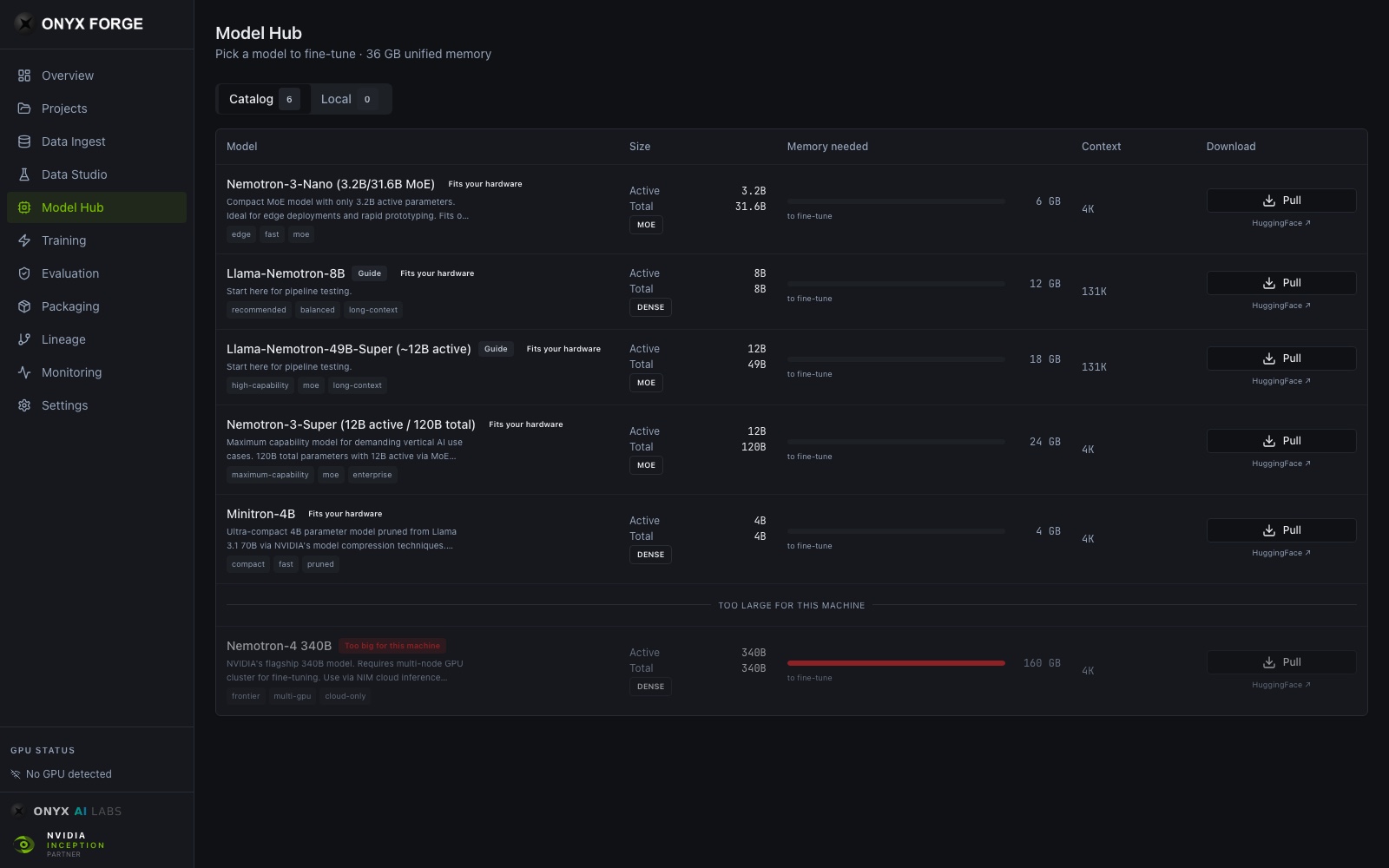
Model Hub — catalog sized to your actual hardware
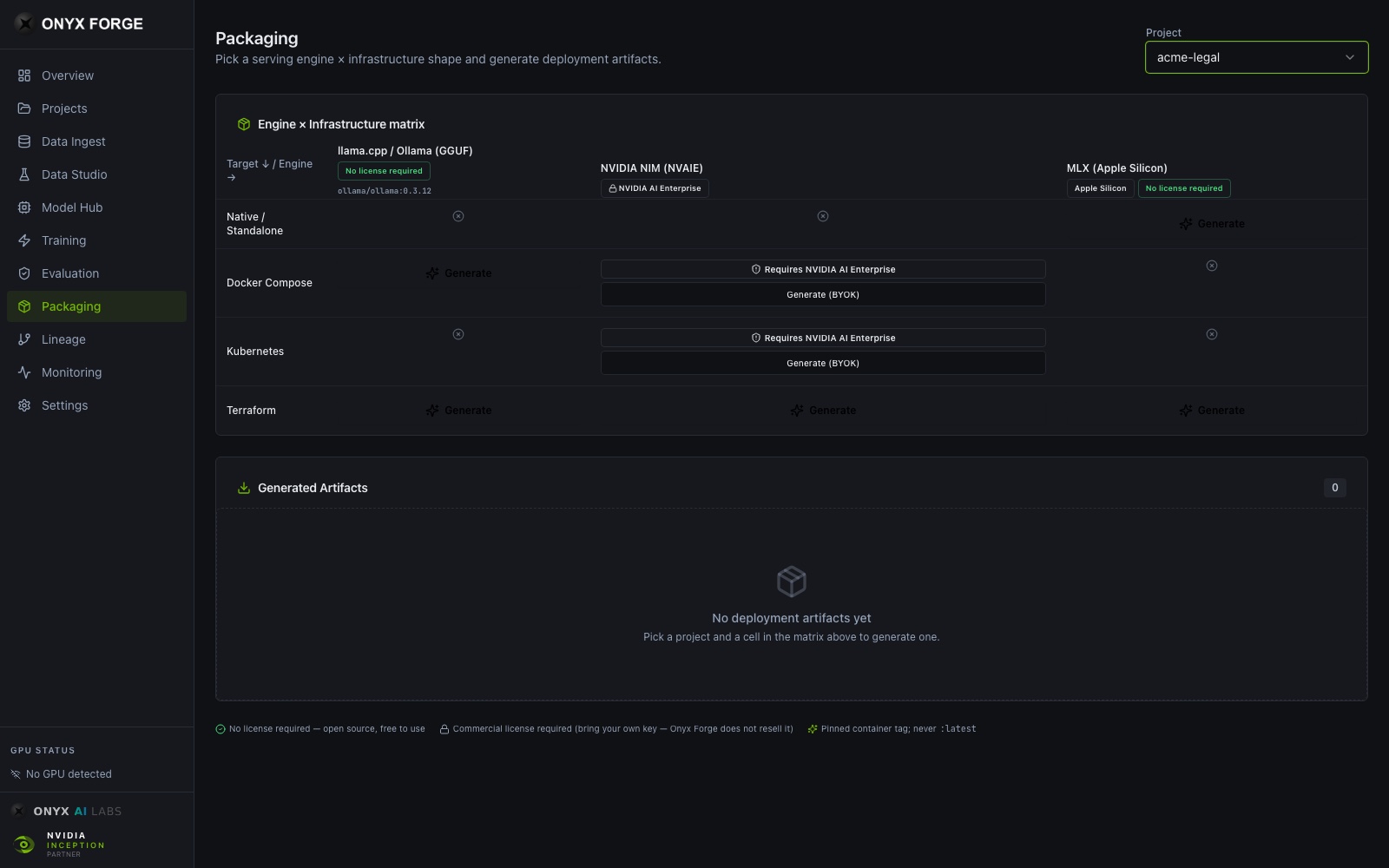
Packaging — engine × infrastructure matrix, license status included
Six stages. One dashboard. Full traceability.
Every stage produces verifiable, cryptographically signed artifacts. Eleven dashboard modules give you complete visibility across the entire AI product lifecycle.
Data Ingest
01Parse, chunk, embed, and store documents into the vector database. Supports PDF, DOCX, HTML, JSON, CSV, TXT, and MD. Multiple extraction backends — Fast (text-only), Docling (multimodal), and NV-Ingest (NVIDIA NIM). Outputs RAG-ready vector embeddings.
Data Studio
02Clean, deduplicate, augment, and format your training data. Built-in quality checks, bias detection, and dataset versioning ensure your models are trained on reliable, representative data.
Model Hub
03Choose from a curated catalog of base models — Llama, Mistral, Qwen, DeepSeek, Nemotron — or bring your own. Automated benchmarking helps you select the right architecture for your domain.
Training
04Fine-tune using NVIDIA NeMo, Unsloth, or MLX — whichever framework is optimal for your use case. PEFT, LoRA, QLoRA, full fine-tuning — Forge selects the right approach for your data and compute budget.
Evaluation
05Seven benchmark dimensions: accuracy, latency, safety, bias, regulatory alignment, robustness, and domain coverage. Automated evaluation suites produce quantitative scores and detailed failure analysis.
Packaging
06Production-ready deployment packages: quantized GGUF/Ollama/MLX for local and air-gapped use, NVIDIA NIM containers for enterprise GPU serving, and Docker Compose/Kubernetes/Terraform manifests for your own infra. Each package includes model cards and cryptographic integrity receipts.
Multi-backend extraction
Choose the extraction backend that fits your format, quality, and licensing requirements. From fast text-only to NVIDIA NIM-powered multimodal extraction.
| Backend | License | Formats | Status |
|---|---|---|---|
| Fast (text-only) | Apache 2.0 | PDF, DOCX, TXT, MD, HTML | ready |
| Docling (multimodal) | Apache 2.0 | PDF, DOCX, PPTX, Images | available |
| NV-Ingest (NVIDIA NIM) | NVIDIA AI Enterprise | PDF, DOCX, Images, Tables | license required |
Ship anywhere. Prove everything.
Three deployment targets. Cryptographic receipts at every stage. Your model, your infrastructure, your verifiable audit trail.
Local & Open (GGUF · Ollama · MLX)
No license required. Quantized GGUF models for llama.cpp/Ollama, or native MLX packages for Apple Silicon. Run on consumer hardware, edge devices, or fully air-gapped environments.
NVIDIA NIM (NVAIE)
NVIDIA-optimized inference container with TensorRT-LLM acceleration. Requires an NVIDIA AI Enterprise license (bring your own key — Forge does not resell it). Deploy on DGX, cloud GPU instances, or your own hardware.
Infrastructure as Code
Docker Compose, Kubernetes, or Terraform manifests generated straight from the packaging matrix — pinned container tags, never :latest. Pick an engine, pick a target, generate.
Ed25519 Receipts
Every model version, every training run, every evaluation result is signed with Ed25519. Cryptographic proof that your model is exactly what was trained and tested.
Merkle-Batched Audit Trails
Immutable, tamper-evident logs of the entire build pipeline. Merkle tree batching provides efficient verification while maintaining cryptographic integrity across millions of pipeline events.
Built on the full NVIDIA AI platform
Every component of Forge runs on NVIDIA infrastructure — from training frameworks to inference engines to deployment containers. Learn more
NeMo
Model customization framework
NIM
Optimized inference microservices
TensorRT-LLM
LLM inference acceleration
Megatron-Core
Large-scale training
LanceDB
Embedded vector database (default)
NV-EmbedQA
Embedding models
Join the Forge waitlist
Forge runs today on Windows/RTX workstations and Apple Silicon Macs. Tell us which platform you're building on and we'll reach out.
Bring your expertise. We'll build the product.
Forge is in early access. If you have deep domain expertise and want to build a vertical AI product, let's talk.
Talk to us